1、IO模型
在IO模型中,主要可分为同步与异步操作:
在同步 I/O 模型中,I/O 操作是阻塞的,当一个进程或线程执行 I/O 操作时,它会一直等待这个操作完成才继续执行后续的代码。
在异步 I/O 模型中,I/O 操作是非阻塞的,这意味着进程或线程在发起 I/O 操作后会立即返回,可以继续执行其他任务。当 I/O 操作完成时,系统会通过回调函数、事件通知或信号等方式通知进程或线程。
1.1、用户态和内核态
当调用一次 channel.read 或 stream.read 后,会切换至操作系统内核态来完成真正数据读取,是因为实际的 I/O 操作,如从磁盘读取数据或从网络套接字接收数据,是由操作系统内核管理的。
用户态:是应用程序代码运行的地方,受到严格的访问限制,不能直接操作硬件或内存中的某些关键区域。
内核态:操作系统内核运行的地方,拥有对硬件和系统资源的完全访问权限,负责执行系统调用、管理硬件设备、内存和进程调度等任务。
当用户调用channel.read 或 stream.read时,最初的代码执行是在用户态,read 方法内部会触发一个系统调用导致上下文切换,从用户态切换到内核态。
在内核态,操作系统内核会执行实际的 I/O 操作:
- 文件读取:如果是从文件读取,内核会检查文件系统的缓存,如果缓存中有数据则直接返回;否则,会从磁盘读取数据到内核缓冲区,再复制到用户缓冲区。
- 网络读取:如果是从网络套接字读取,内核会检查网络缓冲区,如果有数据则直接返回;否则,会等待网络数据到达。
可见在内核态,实际的I/O操作也是分为了等待数据和复制数据两步。
一旦内核完成数据读取操作,它会将读取到的数据复制到用户态缓冲区,然后返回结果。系统调用完成,切换回用户态。
1.2、阻塞IO
传统的阻塞IO,当一个进程或线程发起 I/O 操作(如读取或写入数据)时,操作会一直等待,直到这个 I/O 操作完成才会继续执行后续的代码。
阻塞IO的工作机制:
- 发起 I/O 请求:进程或线程调用 I/O 操作函数,例如读取文件、从网络套接字读取数据等。
- 进入阻塞状态:如果数据还没有准备好,进程或线程将进入阻塞状态,等待数据准备完成。这意味着 CPU 的控制权会暂时被操作系统收回,直到 I/O 操作完成。(例如调用read方法,客户端还没有准备好信息)
- 内核态处理 I/O:操作系统内核处理实际的 I/O 操作,如从磁盘读取数据或等待网络数据到达。(从用户态转换到内核态)
- 数据准备就绪:一旦数据准备好,操作系统会将数据从内核缓冲区复制到用户缓冲区。
- 返回结果:I/O 操作完成,进程或线程从阻塞状态恢复,继续执行后续代码。

1.3、非阻塞IO
例如前篇提到的ServerSocketChannel,就可以设置模式为非阻塞。当设置为非阻塞时,客户端没有发送消息,服务端不会在read方法处陷入阻塞,而是会立刻返回,如果是在循环中则会不停地进行重试:

1.4、多路复用
多路复用实际上也是属于同步阻塞模式的一种,体现在调用selector.select();方法时,如果没有监听到任何事件则会发生阻塞,直到有事件发生才恢复运行。
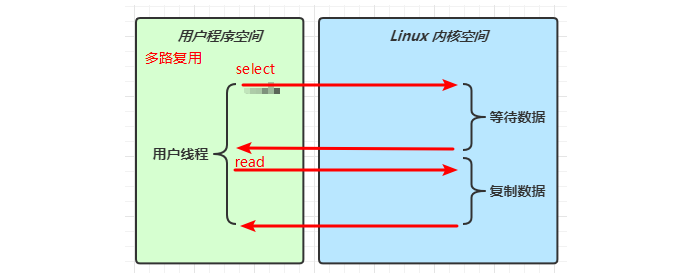
以上三种,均可归类为单线程同步模式
1.5、异步IO
在异步IO中,通常会涉及到多线程,即线程一负责Read操作,而不必一直阻塞等待结果,可以继续执行后面的操作。当Read方法得到结果后,由另一个线程通知线程一读取的结果。
所以异步IO是多线程异步模式的体现。

附文件异步IO的使用案例:
@Slf4j
public class AioDemo1 {
public static void main(String[] args) throws IOException {
try{
AsynchronousFileChannel s =
AsynchronousFileChannel.open(
Paths.get("1.txt"), StandardOpenOption.READ);
ByteBuffer buffer = ByteBuffer.allocate(2);
log.debug("begin...");
s.read(buffer, 0, null, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer attachment) {
log.debug("read completed...{}", result);
buffer.flip();
debug(buffer);
}
@Override
public void failed(Throwable exc, ByteBuffer attachment) {
log.debug("read failed...");
}
});
} catch (IOException e) {
e.printStackTrace();
}
log.debug("do other things...");
System.in.read();
}
}
4.6、多路复用与阻塞/非阻塞IO
上面的案例都是以单事件举例,无法看出多路复用相比较于传统阻塞/非阻塞IO的优势。
假设我们建立了两个连接,在处理第二个连接的read事件前,必须要先将第一个连接的read事件处理完成,如果第一个连接的read方法在阻塞,那么第二个连接的read则永远无法执行。
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(true);
serverSocketChannel.bind(new InetSocketAddress(8080));
List<SocketChannel> clients = new ArrayList<>();
while (true){
SocketChannel channel = serverSocketChannel.accept();
if (channel != null){
clients.add(channel);
}
Iterator<SocketChannel> iterator = clients.iterator();
while (iterator.hasNext()) {
SocketChannel client = iterator.next();
try {
ByteBuffer buffer = ByteBuffer.allocate(1024);
int bytesRead = client.read(buffer);
if (bytesRead == -1) {
// 客户端关闭连接
} else if (bytesRead > 0) {
// 处理读取到的数据
}
} catch (IOException e) {
// 处理异常,关闭通道
iterator.remove();
try {
client.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}而使用Selector实现多路复用进行改进,假设和上面发生一样的场景,连接一的read没有接收到客户端的信息,但是连接二接收到了,那么selector.select();方法就会解除阻塞,直接执行连接二的可读事件。无需等待连接一接收到客户端的信息。
// 创建 ServerSocketChannel 并配置为非阻塞模式
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false);
serverSocketChannel.bind(new InetSocketAddress(8080));
// 打开 Selector 并将 ServerSocketChannel 注册到 Selector 上,监听连接事件
Selector selector = Selector.open();
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
// 等待事件发生(阻塞直到有事件发生或超时)
selector.select();
// 获取所有发生的事件的 SelectionKey
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectedKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 移除当前 SelectionKey,避免重复处理
iterator.remove();
try {
// 处理事件
if (key.isAcceptable()) {
// 有新连接请求,接受连接并配置为非阻塞模式
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel socketChannel = server.accept();
socketChannel.configureBlocking(false);
// 将新的 SocketChannel 注册到 Selector 上,监听读事件
socketChannel.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
// 有数据可读,读取数据
}
}
} catch (IOException e) {
// 处理异常并关闭通道
key.cancel();
key.channel().close();
}
}
}2、零拷贝
零拷贝的目的是减少数据在应用程序和操作系统之间传输时的复制次数,从而提高系统性能。
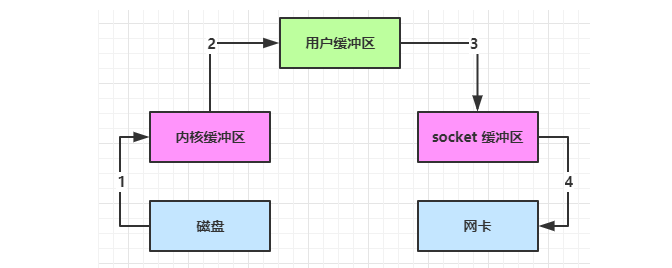
在传统的IO中数据从磁盘传输到网络,并非直接一步到位,而是要经历以下的过程:
- 磁盘到内核缓冲区:操作系统将数据从磁盘读取到内核空间的缓冲区。
- 内核缓冲区到用户缓冲区:数据从内核缓冲区复制到用户空间的缓冲区(应用程序缓冲区)。
- 用户缓冲区到内核缓冲区:应用程序处理数据后,将数据从用户空间的缓冲区复制回内核空间的缓冲区,以便通过网络发送。
- 内核缓冲区到网络:最后,数据从内核空间的缓冲区传输到网络设备,发送到目的地。
在上面的传输过程中,涉及到了内核缓冲区和用户缓冲区 切换的问题,总共切换了三次,同时也经历了四次拷贝操作。
- 用户缓冲区:位于应用程序的地址空间内,可以直接被应用程序访问和操作,由应用程序负责分配和释放内存。可以通过普通的内存读写操作来访问数据。
- 内核缓冲区:位于操作系统的内核空间内,普通应用程序无法直接访问。由操作系统内核管理和控制,包括内存的分配和释放。应用程序无法直接访问内核缓冲区的数据。
用户态与内核态的切换越频繁,拷贝操作越多,效率就越低。
NIO的ByteBuffer,就对其进行了优化:
ByteBuffer具体有两个实现:
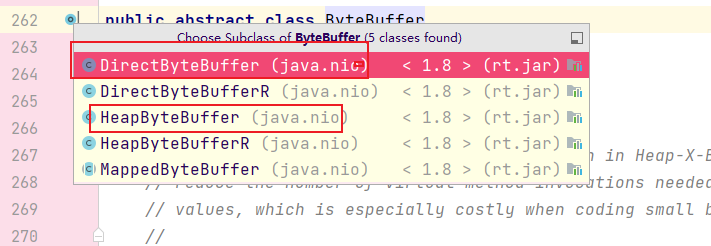
简单的说,HeapByteBuffer的数据存储在 Java 堆内存中,由 Java 虚拟机(JVM)进行管理。而DirectByteBuffer的数据存储在 JVM 之外的直接内存中,通过本地方法库(Native Libraries)进行管理。
DirectByteBuffer 在实现零拷贝时具有明显的优势:
文件传输:在文件传输时,可以使用 FileChannel的TransferTo或 TransferFrom方法,直接将文件内容传输到网络套接字或另一个文件通道,这些方法在内部使用了零拷贝技术,通过直接内存避免了数据复制。
网络传输:在网络传输时,可以利用 DirectByteBuffer 直接将缓冲区数据传输到 SocketChannel,而无需将数据先复制到 JVM 堆内存中,然后再传输,从而提高了传输效率和性能。
共同点在于省去了将数据从内核缓冲区->用户缓冲区->内核缓冲区的步骤,而是直接在两个内核缓冲区之间进行转换。
此外还有使用DMA进行零拷贝优化的:
DMA 是硬件支持的技术,可以让外设(如磁盘或网络接口卡)直接将数据传输到内存,而不需要经过 CPU。避免了数据在内核和用户空间之间的复制。

![[环境配置]vscode通过ssh连接autodl进行项目开发](https://img-blog.csdnimg.cn/img_convert/c5e1dbc898e3463aac03e89c1f82a5f1.png)

